
А сколько проработает ваша система? Это можно посчитать!
Уважаемые читатели Low-voltage Blog! В первой статье о создании систем видеонаблюдения я утверждал, что у проектировщика есть возможность посчитать вероятность работы системы за заданный промежуток времени. Сегодня мы обсудим этот вопрос подробней: с объяснениями «на пальцах» и страшными формулами 🙂 .
Содержание:
1. Термины
1.1 Коэффициент готовности
1.2 Средняя наработка на отказ
1.3 Среднее время восстановления
2 Метод расчёта коэффициента готовности
2.1 Система без резервирования элементов
2.2 Система со 100% резервированием элементов
2.3 Система с частичным резервированием
3 Рекомендации по выбору оборудования и общие выводы
3.1 Рекомендации при проектировании
3.2 Выводы для заказчиков и подрядчиков
Кому адресован этот блог и почему моему мнению можно доверять.
Мои контакты — пишите по любым интересующим вопросам, в том числе предложения о сотрудничестве.
Почему важно понимать вероятность работоспособности системы безопасности и других слаботочных систем в заданный промежуток времени? Очень просто — системы созданы, чтобы решить совершенно конкретную задачу заказчика (это в идеале 🙂 ). Если система не работает — она не решает эту задачу, проблему и т.п. Заказчик терпит убытки, вынужден принимать дополнительные меры безопасности и т.п. При заказе систем часто возникает вопрос — какого класса оборудование нужно взять? Нужно ли резервировать оборудование, и если нужно — то какое именно? Как обосновать перед заказчиком выбор оборудования и степень резервирования?
Ответом на все эти вопросы мы сегодня и займемся.
Статья основана на моей ранее изданной публикации на портале sec.ru. По уже озвучиваемым причинам сейчас она не доступна, как и весь портал. Поэтому публикую её в чуть измененном виде в Low-voltage Blog.
Существует класс заказчиков, для которых цена не является основополагающим фактором при согласовании технических решений. Как правило речь в таких случаях идет о крупных системах. Заказчик может руководствоваться различными соображениями. Чаще всего — стоимостью владения системой и рисками / убытками от неработоспособности системы. В таком случае в ТЗ прописывается желаемый коэффициент готовности системы (Instantaneous availability function) по ГОСТ 27.002-2015 Надежность в технике (ССНТ). Термины и определения.
Данная статья — попытка кратко описать методику обоснования выбора технических решений, особенности проектирования систем с учетом заданного коэффициент готовности, а так же преимущества данного подхода для заказчика перед стандартными подходами (использовать проверенное оборудование; оборудование, на которое есть максимальная скидка; самое дешёвое и т.п.).
1. Термины
Для начала необходимо определиться с терминами.
1.1 Коэффициент готовности
Коэффициент готовности (Instantaneous availability function) — вероятность того, что объект окажется в работоспособном состоянии в произвольный момент времени. Кроме планируемых периодов, в течение которых применение объекта по назначению не предусматривается. Практически коэффициент готовности определяется через среднее суммарное время простоя за заданный интервал времени. Коэффициент готовности Kг =(T – tпΣ) /T, где tпΣ — суммарное время простоя, а T — заданный интервал времени.
К примеру, если заказчик хочет получить систему, суммарное время простоя (неработоспособности) которой в год не должно превышать 1 день, то в задании на проектирование указывается Kг=(365-1)/365 = 0,9973. Можно убедится, что для заказчика в использовании коэффициента готовности нет особой сложности. Он интуитивно понятен, и при этом является комплексным показателем надежности системы. И пожалуй самое важное для заказчика — заявленные данные подрядчика легко проверяются на практике. Для этого достаточно скрупулезно записывать время простоя при эксплуатации, за исключением времени технического обслуживания и т.п., как видно из определения. Проверяемость данных — хорошая гарантия для заказчика, что подрядчик будет максимально тщательно относится ко всем заявляемым характеристикам оборудования.
1.2 Средняя наработка на отказ
Средняя наработка на отказ Mean operating time between failures (MTBF) — отношение суммарной наработки восстанавливаемого объекта к математическому ожиданию числа его отказов в течение этой наработки. Фактически речь идет среднем времени нормального функционирования изделия. Оно вычисляется как отношение общего времени, в течение которого изделие находилось в эксплуатации (t), к общему количеству учитываемых отказов, F, которые возникли в течение времени t. MTBF= t / F(t) = 1 / λ, где λ — интенсивность отказов. Есть правда нюанс — отказ отказу рознь, надо различать учитываемые и не учитываемые отказы. Учитываемый отказ изделия является отдельным отказом, который влечёт потерю способности изделия выполнять требуемую функцию в связи с одним из нижеследующих событий:
- ошибка или поломка изделия, когда оно эксплуатируется в пределах установленных проектом предельных рабочих характеристик и условий окружающей среды;
- неправильная эксплуатация, обслуживание или испытание изделия, по причине предоставленной Подрядчиком документации.
Не учитываемый отказ изделия — любая ситуация отказа изделия, которая не входит в определение «учитываемого отказа», представленного выше, например:
- отказ, вызванный неправильным функционированием другого оборудования;
- отказ, вызванный человеческой ошибкой, за исключением случаев, когда он подпадает под определение «учитываемый отказ»;
- отказ, вызванный функционированием изделия за пределами своих проектных рабочих характеристик или условий окружающей среды.
На сегодняшний день данные по MTBF оборудования предоставляются большинством зарубежных и многими отечественными производителями. Так что особо останавливаться на данном параметре не будем. Отмечу только, что для центрального и периферийного оборудования величина MTBF может существенно отличаться, и это нормально. Безотказность работы центрального оборудования важнее для работоспособности системы в целом, нежели периферийного. Естественно, данные рассуждения перестают работать, если подрядчик начинает “кроить” систему. Экономить на компонентах (например вместо стоечных серверов использует обычные ПК).
Так же отмечу, что есть прямая связь между классом оборудования и величиной MTBF (естественно, чем выше класс — тем больше MTBF). Нередко заказчик помимо требования о значении коэффициента готовности указывает в задании на проектирование минимальные требования на MTBF оборудования, используемого в проекте. На мой взгляд это гораздо лучше и профессиональней, чем требование о использовании конкретного бренда и тем более конкретной марки оборудования. С одной стороны это ограничивает возможности участников тендера заниматься демпингом, используя некачественное дешевое оборудование. С другой стороны оставляет профессионалам возможность заниматься собственно проектной работой — подбирать оборудование в соответствии с задачей и техническим заданием).
1.3 Среднее время восстановления
Среднее время восстановления Mean time to repair (MTTR) — математическое ожидание времени восстановления работоспособного состояния объекта после отказа. Фактически речь идет о продолжительности корректирующего технического обслуживания – сумме периодов времени, которые были затрачены на обнаружение и локализацию отказа, демонтаж или ремонт дефектов оборудования, и выполнение необходимых проверок для восстановления нормальной работы оборудования. На мой взгляд сюда же нужно включать время заказа и доставки отказавшего оборудования (при отсутствии его в ЗИПе), если ремонт не возможен. На практике MTTR вычисляют как отношение общего времени, затраченного на оперативное корректирующее техническое обслуживание Tmc, которое было потрачено в течение заданного периода времени (t) для множества идентичных элементов, к общему числу учитываемых отказов F, которые потребовали корректирующего техобслуживания для этого множества элементов в рассматриваемом интервале времени.
MTTR= Tmc(t) / F(t) = 1 / µ, где µ: интенсивность восстановления.
К сожалению, с MTTR ситуация значительно хуже, чем с MTBF. Мне данные по MTTR оборудования попадались крайне редко. Поэтому зачастую данный параметр приходится прикидывать самостоятельно. Для этого общее время MTTR разбивается на следующий составляющие:
- обнаружение
- локализация
- демонтаж неисправного оборудования
- монтаж аналогичного из ЗИПа
- регулировка / настройка.
При отсутствии для данного типа оборудования ЗИПа, на мой взгляд, к предыдущим составляющим MTTR необходимо добавлять время заказа и поставки оборудования. Только так мы получим объективный коэффициент готовности системы (и соответственно правильное понимание надежности системы).
Как и в случае с MTBF, MTTR коррелирует с классом оборудования, хотя уже и в меньшей степени. Только зависимость для MTTR обратная — чем выше класс оборудования, тем MTTR меньше. За счёт чего это достигается? Есть разные факторы: системы высокого класса обычно имеют функции:
- диспетчеризации (что положительно сказывается на времени обнаружения)
- само-диагностики (уменьшает время локализации неисправности)
- центрального управления (что зачастую позволяет просто загружать все настройки вышедшего из строя оборудования без необходимости производить пусконаладочные работы)
- оборудование — свойствами модульности (например, возможность легкой замены блоков питания стоечного сервера — что ускоряет демонтаж неисправного модуля и монтаж запасного).
Но, как я уже неоднократно отмечал, на MTTR сильно влияют и чисто организационные моменты:
- наличие квалифицированного и обученного персонала у заказчика (или привлечение аутсорсинга подрядчика), желательно периодически тренируемого на действия при тех или иных нештатных ситуациях в системе
- наличие правильно сформированного ЗИПа
- и др.
Поэтому при написании задания на проектирование важно учитывать не только как систему реализовать, но и как её в дальнейшем успешно эксплуатировать.
2 Метод расчёта коэффициента готовности
Любые системы можно условно разделить на последовательные, параллельные и последовательно-параллельные.
2.1 Система без резервирования элементов
Если отказ одного элемента оборудования приводит к отказу всей системы, и, если отказы не зависят друг от друга, то вся система называется последовательной. Фактически, речь идет о системе, в которой полностью отсутствует резервирование элементов.
Для наглядности представим центральную часть системы видеонаблюдения, состоящую из:
- энкодеров, осуществляющих запись с видеокамер
- декодеров, выводящих нужные видеопотоки на видеостену
- сетевого менеджера, управляющего всем этим оборудованием.
Для такой системы коэффициент готовности будет вычисляться следующим образом:
")
Коэффициент готовности для последовательных систем (без резервирования)
Т.е., к примеру, если система состоит из 1-го сетевого менеджера, 10 энкодеров и 10 декодеров, то Kг сист.= Kг сет.мен.* Kг энк.10 * Kг дек.10. Из приведенной формулы можно уже сделать первые очевидные выводы: надежность тем выше, чем больше MTBF и меньше MTTR, и тем меньше, чем больше элементов в последовательной системе, поскольку Kг всегда меньше 1. Соответственно чем система сложнее (больше элементов), тем труднее добиться высокой надежности.
2.2 Система со 100% резервированием элементов
Если функционирование 1-го из n элементов системы достаточно для функционирования всей системы, то вся система называется параллельной. Фактически, речь идет о системе со 100% резервированием. Для такой системы коэффициент готовности будет вычисляться следующим образом:
")
Коэффициент готовности для параллельной системы (полное резервирование элементов)
Останавливаться на параллельной системе долго не будем, потому как чисто параллельные системы встречаются не часто. Пример — система передачи извещений на пульт центральной охраны по нескольким независимым каналам связи отдельными устройствами.
2.3 Система с частичным резервированием
Для системы с резервированием элементов, которая представлена последовательно-параллельной системой, средний коэффициент готовности будет равен:
")
Коэффициент готовности для последовательно-параллельной системы (частичное резервирование)
где: Ki — количество компонентов с резервированием в подсистеме i, S — количество подсистем в полной системе.
Блок схема надёжности последовательно-параллельной системы (MTBF — µ, MTTR — λ).
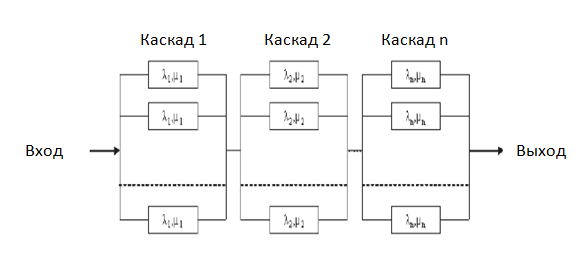
Блок-схема последовательно-параллельной системы
Для нашего примера с системой видеонаблюдения, мы должны будем резервировать элементы общей системы. Например, сетевой менеджер, энкодеры, декодеры. Допустим, мы остановились на системе с кратностью резервирования n+1, в таком случае коэффициент готовности будет равен:
Kг сист. = (1-(1-Kг сет.мен.)2) * (1-(1-Kг энк.)2) * Kг энк.9 * (1-(1-Kг дек.)2 * Kг дек.9.
Но тут нужно учесть один момент: данная формула применима, если для заказчика важна надежность как функции записи видеопотоков, так и функция отображения их на видеостене. Если, к примеру, отображение видео на видеостене — функция второстепенная, то для расчета коэффициента готовности декодеры вполне можно не учитывать, величина коэффициента готовности при этом возрастёт:
Kг сист. = (1-(1-Kг сет.мен.)2) * (1-(1-Kг энк.)2) * Kг энк..
Данный факт ещё раз подчёркивает, что только заказчик может правильно расставить приоритеты по надёжности для своей системы. Задача подрядчика учесть пожелания заказчика и грамотно рассчитать коэффициент готовности и подобрать оборудование с учётом этого.
3 Рекомендации по выбору оборудования и общие выводы
3.1 Рекомендации при проектировании
Алгоритм проектирования для достижения заданного коэффициента готовности может быть, например, такой.
- Если система достаточно крупная (сотни элементов), то имеет смысл отдельно рассчитывать коэффициент готовности для центральной части системы и периферии. Иначе влияние ваших технических решений на общую надежность системы будет не заметно на фоне большого количества не резервируемых элементов периферии. К тому же, как я уже отмечал выше, для большой части заказчиков надежность работы центральной части системы приоритетней, нежели периферии. Для примера с видео наблюдением работа энкодера и сетевого менеджера значительно важнее и приоритетней, чем одной случайно взятой видеокамеры, когда счет идет на сотни видеокамер и десятки энкодеров. Самой критичной частью системы этом случае будет сетевой менеджер. Именно его функции важно резервировать.
- После того, как принято решение рассчитывать ли отдельно коэффициент готовности для центральной и периферийной части системы, необходимо для каждого типа оборудования (для видео наблюдения это энкодеры, декодеры, сетевые менеджеры, и т.д.) найти сведения о MTBF и MTTR данного типа оборудования. Подсчитать его общее количество. Вычислить коэффициент готовности единичного оборудования каждого типа и для каждого типа оборудования — общий коэффициент готовности с учетом наличия или отсутствия резервирования по перечисленным выше формулам для последовательной (если нет резервирования), параллельной (если 100% резервирование) или последовательно-параллельной (для частичного уровня резервирования) системы.
- Коэффициент готовности всей системы в целом будет равен произведению общих коэффициентов готовности всех типов оборудования.
- Далее начинается процесс оптимизации технических решений для получения нужного коэффициента готовности системы.
Важно отметить, что сделав небольшую и не сложную таблицу в офисной программе мы получаем возможность практически мгновенно вычислять влияние принимаемых проектировщиком подрядчика решений на надежность системы в целом, приходя к нужной конкретному заказчику заданной надежности быстро и эффективно.
3.2 Выводы для заказчиков и подрядчиков
Итак, подведем итоги.
Коэффициент готовности является комплексных показателем надежности системы. Его можно вычислить двумя способами: теоретически через MTBF и MTTR оборудования системы при проектировании (вычисляется подрядчиком) и при эксплуатации системы практически через среднее суммарное время простоя (вычисляется заказчиком). Таким образом, коэффициент готовности обладает свойством проверяемости. Данный коэффициент позволяет подрядчику обосновывать принимаемые технические решения исходя из требуемой заказчиком надежности, а заказчику эффективно инвестировать собственные средства учитывая риски неработоспособности системы в течении n-го времени.
Для того, чтобы подрядчик смог грамотно рассчитать коэффициент готовности, заказчику необходимо оценить какое максимальное время простоя допустимо для той или иной функции системы на достаточно большом промежутке времени (обычно в течении года, но не обязательно, можно и любой другой период). К примеру заказчик владеет торгово-развлекательным центром (ТРЦ) и сдает имеющиеся помещения арендаторам. Чтобы грамотно составить задание на проектирование на систему автоматики жизнеобеспечения здания (ИТП, холодоснабжение, энергоснабжение и т.п.), нужно рассчитать допустимые убытки от неработоспособности или не полной работоспособности данных систем из-за недоступности соответствующих функций системы автоматики. Например, холодоснабжение актуально летом. Заказчик может прописать в задании на проектирование, что система автоматики для данной функции не должна находиться в отключенном состоянии дольше 1 дня в течении 3-х месяцев. А отсутствие автоматического управления отоплением заказчик готов терпеть не больше 3-х дней в течении 8-ми месяцев отопительного сезона. Отсутствие же управления и диспетчеризации системы электроснабжения допустимо не более 5-ти дней в течении года. Такие формулировки вполне достаточны для расчета надежности системы автоматики для ТРЦ. Думаю очевидно, что подобные рассуждения не сложно привести любому собственнику, заказчику систем у подрядчика.
Проектировщику подрядчика необходимо иметь в виду следующие соображения. Чем крупнее система, тем сложнее добиться надежности ее работы и, соответственно, высокого коэффициента готовности. Поэтому для крупных систем необходимо выбирать оборудование с высоким MTBF и низким MTTR. Находить в системе «узкие» места и резервировать оборудование. Рассчитать и включить в смету необходимый для надежной работы системы ЗИП, дать рекомендации к численности и квалификации обслуживающего персонала, периодичности технического обслуживания. Если система очень крупная (сотни единиц оборудования), то оправдано раздельное вычисление коэффициента готовности для центральной части системы и для периферии.
На сегодня эта вся информация, которой я хотел с вами поделиться, спасибо за уделенное время!
Уважаемые читатели блога, если Вы заметили в статье неточность, сложность в изложении материала либо некорректность используемых терминов — прошу написать в комментариях либо в личном сообщении, все замечания будут обязательно учтены и по-возможности исправлены все недочёты.
Жду ваших вопросов, комментариев и предложений.
Жмите кнопки социальных сетей, подписывайтесь на email рассылку, добавляйте блог в свою RSS-ленту, вступайте в группы блога в социальных сетях!
Все материалы данного блога принадлежат его автору. Использование без ссылки на данный блог с указанием авторства не допускается!